
もくじ
けど、そんな中で悩むことは、
・関数やVBAで効率的に行いたいがやり方がわからない。
ですよね。
今回はそんなお悩みを解決する
Excelで文字列からひらがなのみを抽出・削除する方法について
まとめます!
関数文字列からひらがなのみを抽出する
関数文字列からひらがなのみを抽出・削除する方法について説明をします。
方法は文字列から一文字づつ取り出し、ひらがなか否かを判定し、抽出であればひらがなと判定した値のみ出力し、削除であればひらがなと判定できなかった文字のみを出力するものです。
今回のサンプルデータは以下の通り、各全角文字、半角カタカナの混合のパターンでひらがなのみを抽出・削除していきます。
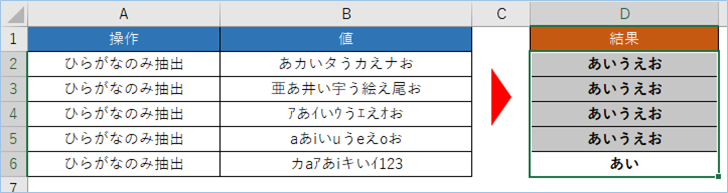
ひらがなのみ抽出
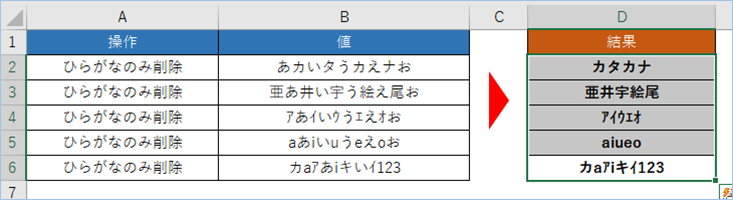
ひらがなを削除
関数その1:文字列からひらがなのみを抽出する
MID関数で取得した文字列から1文字づつ取り出し、CODE関数でひらがなかどうか判定し、ひらがなである場合はそのままの値、ひらがなでない場合は””を出力し、出てきた結果をTEXTJOIN関数で結合する方法となります。
全角カタカナとひらがなを判別しひらがなのみ抽出する
サンプルではB2に全角カタカナとひらがなの文字混合の値を入力しています。
数式は以下の通りです。
出力するD2へ数式を入力します。

=TEXTJOIN("",TRUE,IF(CODE(MID(B2,SEQUENCE(LEN(B2)),1))<=9331,MID(B2,SEQUENCE(LEN(B2)),1),""))関数について説明します。
まず、セルに入力されている文字を一文字づつ取り出していきます。
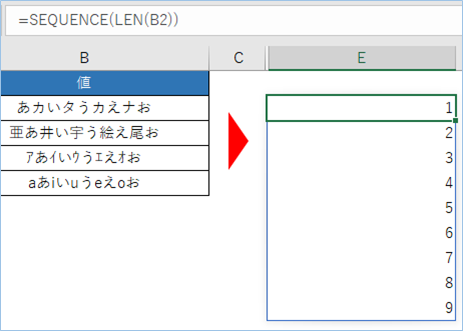
使う関数はSEQUENCE関数で、連続した配列を作成する関数です。
その値にLEN関数でB2の文字数を取得し、その分の配列を作成します。
B2の値は9文字ですので、9個分の配列ができる形となります。
=SEQUENCE(LEN(B2))
次にMID関数を使い、抽出したい文字を指定します。
MID関数は取得開始位置の中間指定が可能な関数です。
以下のように指定することで抽出したい文字を指定します。
第二引数の開始位置に配列を指定すると配列の値を取得し、その値を位置番号として文字列の文字を取得できます。
MID関数の第二引数に「SEQUENCE(LEN(B2))」、文字数は1文字を指定します。
=MID(B2,SEQUENCE(LEN(B2)),1)結果は以下のようになります。
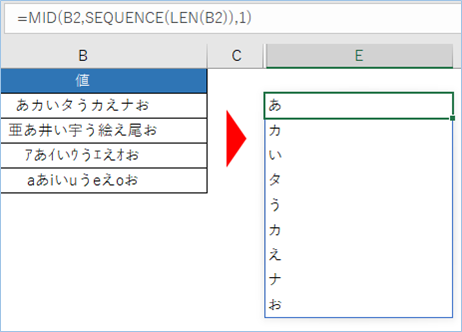

次にMID関数が取得した文字をCODE関数で文字コードに変換します。
CODE(<文字>)
CODE関数とは指定した文字列の文字コード番号を返す関数です。
ひらがなの文字コード番号は9249-9331となりますので、取得した文字が文字コードの範囲内かどうかで判定していきます。
B2に入力されている全角カタカナのコード範囲は9504~9587となりますので、境界線を9331とし、9331以下であるかどうかでひらがなの判定をしています。
| 文字の種類 | CODE範囲-開始 | CODE範囲-終わり |
| 半角数字 | 48 | 57 |
| 半角英字(大文字) | 65 | 90 |
| 半角英字(小文字) | 97 | 122 |
| 半角カタカナ | 161 | 223 |
| 全角数字 | 9007 | 9018 |
| ひらがな | 9249 | 9331 |
| 全角カタカナ | 9505 | 9590 |
| 全角漢字 | 12321 | 29734 |
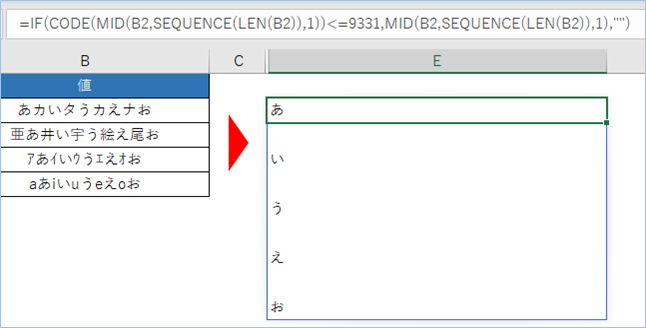
仕上げにTEXTJOIN関数で文字を結合していきます。
TEXTJOIN関数の構文は以下の通りです。
サンプルでは区切り記号に空文字を指定し、空の文字は無視、という条件にしています。
=TEXTJOIN("",TRUE,<ひらがな判定文字>1,<ひらがな判定文字>2,・・・)実行結果を確認してみましょう。
はい、ひらがなのみが抽出されましたね。

漢字とひらがなを判別しひらがなのみ抽出する
そのままD3へドラッグし、2行目にも数式をコピーしましょう。
次はひらがなと漢字の混合となります。
漢字のコード範囲は12321~29734となりますので、全角カタカナ判別の条件(9331以上)がそのままマッチすることになります。
| 文字の種類 | CODE範囲-開始 | CODE範囲-終わり |
| 半角数字 | 48 | 57 |
| 半角英字(大文字) | 65 | 90 |
| 半角英字(小文字) | 97 | 122 |
| 半角カタカナ | 161 | 223 |
| 全角数字 | 9007 | 9018 |
| ひらがな | 9249 | 9331 |
| 全角カタカナ | 9505 | 9590 |
| 全角漢字 | 12321 | 29734 |
問題ありませんね。
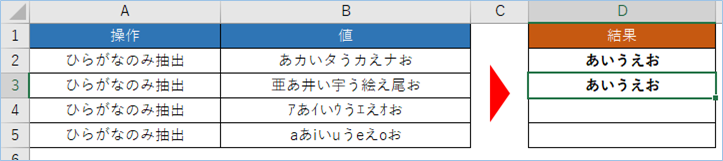
半角カタカナとひらがなを判別しひらがなのみ抽出する
D4へ数式をドラッグしましょう。
今度は半角カタカナの混合となりますが、半角カタカナ範囲は161-223となりますので、前回の全角カタカナの条件にマッチしません。
| 文字の種類 | CODE範囲-開始 | CODE範囲-終わり |
| 半角数字 | 48 | 57 |
| 半角英字(大文字) | 65 | 90 |
| 半角英字(小文字) | 97 | 122 |
| 半角カタカナ | 161 | 223 |
| 全角数字 | 9007 | 9018 |
| ひらがな | 9249 | 9331 |
| 全角カタカナ | 9505 | 9590 |
| 全角漢字 | 12321 | 29734 |
結果。
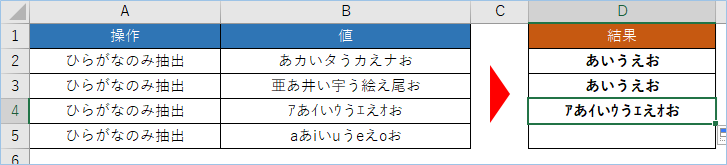
そこでひらがなのコード範囲の上限である、9249以上であるかという条件を追加します。
=TEXTJOIN("",TRUE,IF(CODE(MID(B4,SEQUENCE(LEN(B4)),1))<=9331,IF(CODE(MID(B4,SEQUENCE(LEN(B4)),1))>=9249,MID(B4,SEQUENCE(LEN(B4)),1),""),""))ひらがなのみとなりましたね。

半角英字とひらがなを判別しひらがなのみ抽出する
次は半角英字との混合文字の判定となります。
半角英字のコード範囲は65-122ですので、ひらがなと同じ条件でひらがなの判定ができていることがわかります。
| 文字の種類 | CODE範囲-開始 | CODE範囲-終わり |
| 半角数字 | 48 | 57 |
| 半角英字(大文字) | 65 | 90 |
| 半角英字(小文字) | 97 | 122 |
| 半角カタカナ | 161 | 223 |
| 全角数字 | 9007 | 9018 |
| ひらがな | 9249 | 9331 |
| 全角カタカナ | 9505 | 9590 |
| 全角漢字 | 12321 | 29734 |
問題ありませんね。
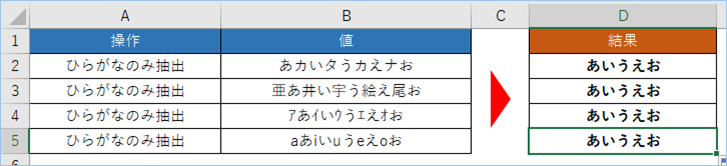
半角英数字、全角/半角カタカナ、漢字の混合文字からひらがなのみ抽出する
D6へ数式をドラッグしましょう。
最後は半角英数字、全角/半角カタカナ、漢字の混合文字からひらがなのみを抽出します。
問題ありませんね。
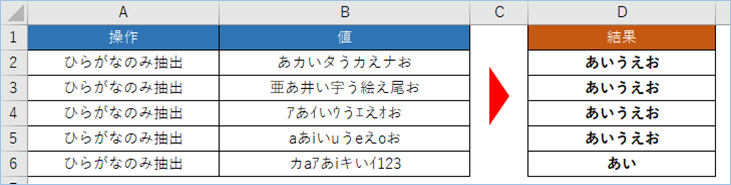
関数その2:文字列からひらがなのみを削除する
次は文字列の内、ひらがなのみを削除します。
MID関数で取得した文字列から1文字づつ取り出し、CODE関数でひらがなかどうか判定し、ひらがなである場合は空白の””、ひらがなでない場合はそのままの値を出力し、出てきた結果をTEXTJOIN関数で結合する方法となります。
全角カタカナとひらがなを判別しひらがなのみ削除する
サンプルでは抽出と同じくB2に全角カタカナとひらがなの文字混合の値を入力しています。
数式は以下の通りです。
出力するD2へ数式を入力します。

=TEXTJOIN("",TRUE,IF(CODE(MID(B2,SEQUENCE(LEN(B2)),1))>9331,MID(B2,SEQUENCE(LEN(B2)),1),""))IF関数以外の処理は抽出と同様であるため割愛します。
条件判定のIF関数ですが、各文字コード判定の不等号を反転させ、抽出時と反対の条件(ひらがなである場合からひらがなでない場合)にし、ひらがな以外の文字を抽出することにより削除を行っていきます。
ひらがなのコード範囲は9249-9331となりますので、境界線を9331とし、9331より大きい場合抽出する条件にすることにより全角カタカナを除いたひらがなだけが抽出されるようにしています。
| 文字の種類 | CODE範囲-開始 | CODE範囲-終わり |
| 半角数字 | 48 | 57 |
| 半角英字(大文字) | 65 | 90 |
| 半角英字(小文字) | 97 | 122 |
| 半角カタカナ | 161 | 223 |
| 全角数字 | 9007 | 9018 |
| ひらがな | 9249 | 9331 |
| 全角カタカナ | 9505 | 9590 |
| 全角漢字 | 12321 | 29734 |
結果を確認しましょう。
はい、全角カタカナが削除されひらがなのみになりましたね。
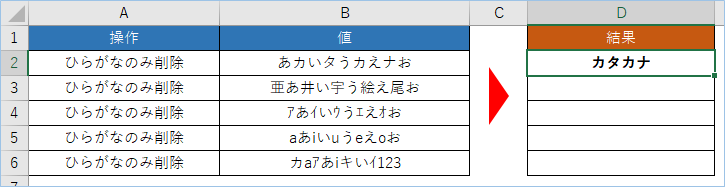
漢字とひらがなを判別しひらがなのみ削除する
そのままD3へドラッグし、2行目にも数式をコピーしましょう。
次はひらがなと漢字の混合となります。
漢字のコード範囲は12321~29734となりますので、全角カタカナ判別の条件がそのままマッチすることになります。
| 文字の種類 | CODE範囲-開始 | CODE範囲-終わり |
| 半角数字 | 48 | 57 |
| 半角英字(大文字) | 65 | 90 |
| 半角英字(小文字) | 97 | 122 |
| 半角カタカナ | 161 | 223 |
| 全角数字 | 9007 | 9018 |
| ひらがな | 9249 | 9331 |
| 全角カタカナ | 9505 | 9590 |
| 全角漢字 | 12321 | 29734 |
問題ありませんね。
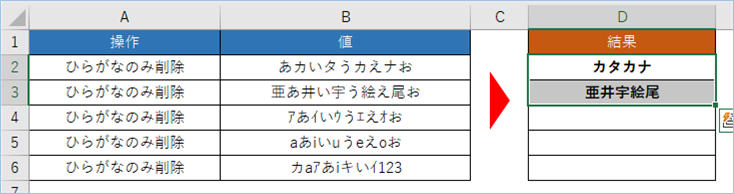
半角カタカナとひらがなを判別しひらがなのみ削除する
D4へ数式をドラッグしましょう。
今度は半角カタカナの混合となりますが、半角カタカナ範囲は161-223となりますので、前回の全角カタカナの条件にマッチしません。
| 文字の種類 | CODE範囲-開始 | CODE範囲-終わり |
| 半角数字 | 48 | 57 |
| 半角英字(大文字) | 65 | 90 |
| 半角英字(小文字) | 97 | 122 |
| 半角カタカナ | 161 | 223 |
| 全角数字 | 9007 | 9018 |
| ひらがな | 9249 | 9331 |
| 全角カタカナ | 9505 | 9590 |
| 全角漢字 | 12321 | 29734 |
そこでひらがなのコード範囲の上限である、9249より下回るかという条件を追加します。
=TEXTJOIN("",TRUE,IF(CODE(MID(B4,SEQUENCE(LEN(B4)),1))>9331,MID(B4,SEQUENCE(LEN(B4)),1),IF(CODE(MID(B4,SEQUENCE(LEN(B4)),1))<9249,MID(B4,SEQUENCE(LEN(B4)),1),"")))半角カタカナのみとなりましたね。
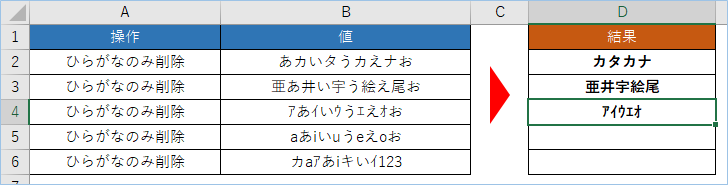
半角英字とひらがなを判別しひらがなのみ削除する
D5へ数式をドラッグしましょう。
今度は英字との混合となりますが、半角英字のコード範囲は65-122となりますので、半角カタカナと同じ条件でマッチすることになります。
| 文字の種類 | CODE範囲-開始 | CODE範囲-終わり |
| 半角数字 | 48 | 57 |
| 半角英字(大文字) | 65 | 90 |
| 半角英字(小文字) | 97 | 122 |
| 半角カタカナ | 161 | 223 |
| 全角数字 | 9007 | 9018 |
| ひらがな | 9249 | 9331 |
| 全角カタカナ | 9505 | 9590 |
| 全角漢字 | 12321 | 29734 |
できましたね。
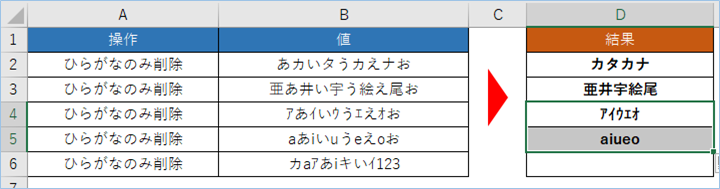
半角英数字、全角/半角カタカナ、漢字の混合文字からひらがなのみ削除する
D6へ数式をドラッグしましょう。
最後は半角英数字、全角/半角カタカナ、漢字の混合文字からひらがなのみを削除します。
問題ありませんね。
VBAで文字列からひらがなのみを抽出・削除する
VBAその1:文字列からひらがなのみを抽出する
VBAで文字列からひらがなのみを抽出してみましょう。
B2からB6まで入力されている値を取得し、 ひらがなの正規表現”[ぁ-ん]”で判定を行いひらがなを抽出、D列へ結果を返します。
以下サンプルコードです。
Sub 文字列からひらがなのみを抽出する()
Dim strTemp As Variant
Dim i As Integer
Dim j As Integer
Dim k As Integer
Dim strMoji As String
Dim strMojiTemp As String
'処理対象のセルをレンジ指定します。
strTemp = Range("B2:B6")
'配列に格納された値すべてを対象に処理します。
For i = LBound(strTemp, 1) To UBound(strTemp, 1)
For j = LBound(strTemp, 2) To UBound(strTemp, 2)
For k = 1 To Len(strTemp(i, j))
strMoji = Mid(strTemp(i, j), k, 1)
If strMoji Like "[ぁ-ん]" Then
strMojiTemp = strMojiTemp & strMoji
End If
Next
Cells(i + 1, j + 3) = strMojiTemp
strMoji = ""
strMojiTemp = ""
Next
Next
End Sub値がある対象レンジ”B2:B6″を変数に指定します。
strTemp = Range(“B2:B6”)
二次元配列に格納された値すべてを対象に処理します。
For i = LBound(strTemp, 1) To UBound(strTemp, 1)
For j = LBound(strTemp, 2) To UBound(strTemp, 2)
正規表現”[ぁ-ん]”でひらがなの判定をおこない、文字数分繰り返します。
For k = 1 To Len(strTemp(i, j))
strMoji = Mid(strTemp(i, j), k, 1)
If strMoji Like “[ぁ-ん]” Then
strMojiTemp = strMojiTemp & strMoji
End If
Next
結果を対象セルへ出漁します。
Cells(i + 1, j + 3) = strMojiTemp
文字列からひらがなのみを抽出できました。
VBAその2:文字列からひらがなのみを削除する
次にVBAで文字列からひらがなのみを削除してみましょう。
B3からB4まで入力されている値を取得し、 ひらがな[ぁ-ん]の正規表現でひらがなの判定を行いひらがな以外を抽出、D列へ結果を返します。
以下サンプルコードです。
Sub 文字列からひらがなのみを削除する()
Dim strTemp As Variant
Dim i As Integer
Dim j As Integer
Dim k As Integer
Dim strMoji As String
Dim strMojiTemp As String
'処理対象のセルをレンジ指定します。
strTemp = Range("B2:B6")
'配列に格納された値すべてを対象に処理します。
For i = LBound(strTemp, 1) To UBound(strTemp, 1)
For j = LBound(strTemp, 2) To UBound(strTemp, 2)
For k = 1 To Len(strTemp(i, j))
strMoji = Mid(strTemp(i, j), k, 1)
If Not strMoji Like "[ぁ-ん]" Then
strMojiTemp = strMojiTemp & strMoji
End If
Next
Cells(i + 1, j + 3) = strMojiTemp
strMoji = ""
strMojiTemp = ""
Next
Next
End Sub値がある対象レンジ”B4:B5″を変数に指定します。
strTemp = Range(“B4:B5”)
正規表現”[ぁ-ん]”でひらがなの判定を行い、抽出時と反対にNotで否定し、ひらがなでない場合に値を出力するようにします。
If Not strMoji Like “[ぁ-ん]” Then
strMojiTemp = strMojiTemp & strMoji
End If
結果を対象セルへ出漁します。
※B4から開始ですので、「i + 3」へ変更しています。
Cells(i + 3, j + 3) = strMojiTemp
実装して実行してみましょう。
文字列からひらがなのみを削除できましたね。
VBAの実装手順
実装手順は以下の通りです。
今回はExcel側にこのVBAを実装します。
①Excelを新規に開き、「開発」タブをクリックし、「VisualBasic」をクリックします。
もしくはショートカットキー「Alt」+「F11」でもOKです。
②標準モジュールを追加します。
左ペインのVBAProjectを右クリックし、「挿入」、「標準モジュール」を選択します。
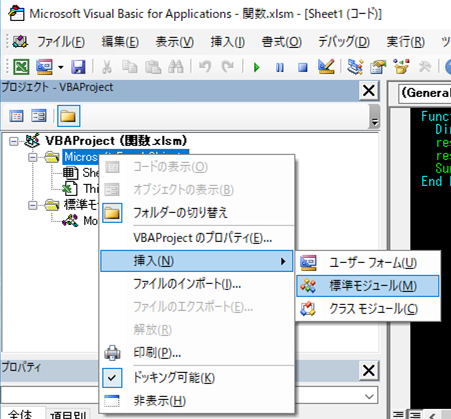
③右ペインのウインドウに上記のVBAを入力します。
こちらで完了です。
VBAを実行する
では早速VBAの実行をしてみましょう。
①「開発」タブの「VBA」をクリックし実行したいマクロを選択し、「実行」をクリックします。
②処理がされたことが確認できれば完了です。
※完了メッセージやステータス管理など必要に応じて実装してもらえばと思います。
さいごに
いかがでしょうか。
今回は、
Excelで文字列からひらがなのみを抽出・削除する方法について
まとめました。
また、他にも便利な方法がありますので、よろしければご参照頂ければと思います。
この記事の関連キーワード















コメントを残す