
もくじ
例えば漢字の「月」とすべきを康煕部首「?」にしてしまい、漢字の「月」に統一したいときなどです。
そんなときに悩ませることは、
・Wordで康煕部首を変換することを手作業でなく一括で処理したいが方法がわからない。
ですね。
特に康煕部首は漢字と見分けがつかわない文字もありますので、目視で判別するには少々難しいです。
そんな作業がたくさんあったらうんざりしますね。
今回はそんなお悩みを解決する、
Word VBAを使い、康煕部首の文字を漢字など別の文字へ置換する方法
についてまとめます。
康煕部首(こうきぶしゅ)とは
康煕部首(こうきぶしゅ)とは漢字の部首を表現する文字となります。
例えば漢字の冠(かんむり)、偏(へん)、旁(つくり)、構(かまえ)などの部分となります。
具体的には下記のように漢字の「月」と康煕部首の「?」や漢字の「自」と康煕部首の「?」やのような文字となります。

ぱっと見、漢字か康煕部首か判断できないですね。
しかし文字コードをみると明らかにちがいます。
=CODE("<文字>")ExcelのCODE関数で文字コードを調べてみますと、
はい、違いますね。
康煕部首「?」:63
漢字「自」:15403
康煕部首「?」:63
康煕部首のやっかいな点は文字化けすること
康煕部首の厄介な点はデータをテキストエディタなどコピペすると文字化けを起こすことがあります。
例えば、Windows環境のWordから、秀丸などのテキストエディタへ康煕部首コピペをすると「?」と表示されてしまいます。
康煕部首はUnicodeですが、その文字コードを含んでいない文字コード指定やフォント指定がされているとソフトウェア側で文字種が判別できないためです。
特に、Microsoft標準であるShift-JISのコードに含まれていないので、Windows環境では結構な頻度で文字化けをしてしまうという訳です。
今回ご紹介する康煕部首の置換処理ですが、Windows環境で実行しますので、この文字化けを回避する処理を加えた上、実現していきたいと思います。

Word VBAで康煕部首を他の文字へ一括置換するイメージ
>Word VBAで康煕部首を他の文字へ一括置換するイメージについて説明をします。
康煕部首を含む文章が記載されたWordドキュメントを用意します。
こんな感じです。

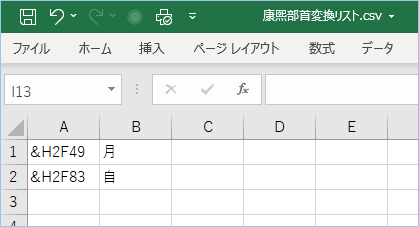
次に康煕部首の文字コード番号と変換したい文字が記載されているCSVファイルを用意します。
CSVファイルを設定したVBAをWordへ実装します。
VBAを実行すると、
康煕部首の文字が別の文字へ一括変換されます。
変更前
変更後

カンタンですね。
早速使ってみましょう。
サンプルのWordドキュメントを準備する
康煕部首を含む文章が記載されたWordドキュメントを用意しましょう。
できたら、任意の場所へ保存します。
康煕部首の文字コード番号と変換したい文字が記載されているCSVファイルを用意する
康煕部首の文字コード番号と変換したい文字が記載されているCSVファイルを用意しましょう。
文字コード番号にする理由は、文字化けを起こす康煕部首の文字をVBAで判別できるようにするためです。
まず、文字コードを確認します。
こちらへアクセスし、左ペインの検索ボックスへ置換したい康煕部首をコピペで入力し、検索します。
https://glyphwiki.org/wiki/GlyphWiki:%e3%83%a1%e3%82%a4%e3%83%b3%e3%83%9a%e3%83%bc%e3%82%b8
文字コードの「****」をコピーします。
文字コード「****」の頭に16進数を表す「&H」を追加します。
続いてCSVファイルへ「,」と置換したい文字を追加します。
サンプルでは、
康煕部首の「?」を漢字の「月」
康煕部首の「?」と漢字の「自」へ変換を行います。
その場合の設定内容は、
&H2F83,自
となります。
拡張子を「csv」にしてCSVファイルを任意の場所へ保存します。
VBAを実装する
続いてWordのVisual Basic EditorへVBAを実装します。
今回のVBAは康煕部首の文字コード番号と変換したい文字のパターンが記載されているCSVファイルを読み込み、そのリスト分置換処理を繰り返すというものになります。
実装にあたり、変更頂きたい箇所は以下です。
・置換リストファイルを指定する
置換リストを格納したパスに書き換えをお願いします。
csvFilePass = “C:\Users\****\Documents\****\康煕部首変換リスト.csv”
VBAソースコードは以下の通りです。
Sub 複数の文字列を置換_康煕部首対応版()
Dim csvFilePass
Dim strBuf As String
Dim tmp As Variant
'置換リストファイルを指定します。
csvFilePass = "C:\Users\****\Documents\****\康煕部首変換リスト.csv"
Open csvFilePass For Input As #1
'CSV内の行数分置換処理を繰り返します。
Do Until EOF(1)
'1行分のデータを読み込みます。
Line Input #1, strBuf
'文字列を","で分割します。
tmp = Split(strBuf, ",")
'検索・置換の設定をおこないます。
With Selection.Find
.ClearFormatting '検索条件から書式を削除します。
.Replacement.ClearFormatting '置換対象の書式を削除します。
.Text = ChrW(tmp(0)) '文字コードを文字へ変換し、検索ワードを代入します。
.Replacement.Text = tmp(1) '置換ワードを代入します。
.Forward = True '文書に対して末尾の方向(順方向)に検索します。
.Wrap = wdFindContinue '先頭(または末尾)に戻って検索をします。
.Format = False 'フォーマット変更を有効する(True)、有効にしない(False)を設定します。
.MatchCase = True '英語の大文字と小文字の区別する(True)、区別しない(False)を設定します。
.MatchWholeWord = False '単語全体を検索対象としない設定にします。
.MatchByte = False '半角と全角を区別する(True)、区別しない(False)を設定します。
.MatchAllWordForms = False '英単語の異なる活用形検索を有効する(True)、有効にしない(False)を設定します。
.MatchWildcards = False 'ワイルドカード(?*など任意の文字)を使った検索を有効する(True)、有効にしない(False)を設定します。
.MatchSoundsLike = False '誤った置換を防止するため、英語のあいまいな検索はOFFにします。
.MatchFuzzy = False '誤った置換を防止するため、日本語のあいまいな検索はOFFにします。
End With
'置換を実行(全て置換)します。
Selection.Find.Execute Replace:=wdReplaceAll
Loop
Close #1
MsgBox "置換が完了しました。"
End Sub実装手順は以下の通りです。
①Wordを新規に開き、「開発」タブをクリックし、
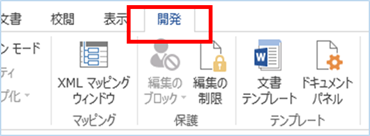
「VisualBasic」をクリックします。
もしくはショートカットキー「Alt」+「F11」でもOKです。
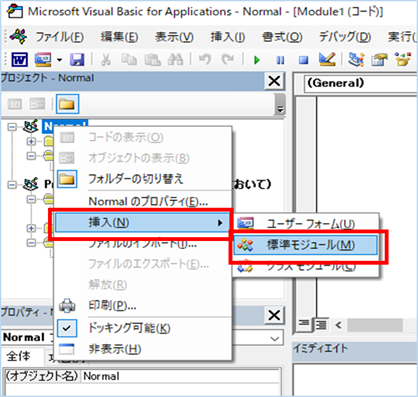
②標準モジュールを追加します。
左ペインの「Nomal」を右クリックし、「挿入」、「標準モジュール」を選択します。
③右ペインのウインドウに上記のVBAを入力します。
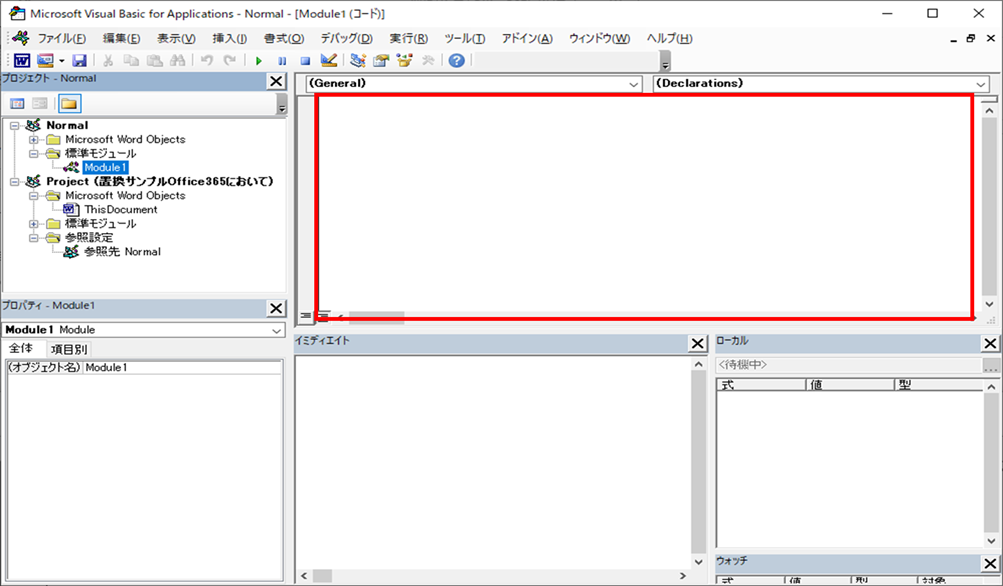
こちらで完了です。
VBAを実行する
早速VBAの実行をしてみましょう。
①「開発」タブの「マクロ」をクリックし「複数の文字列を置換_康煕部首対応版」を選択し、「実行」をクリックします。

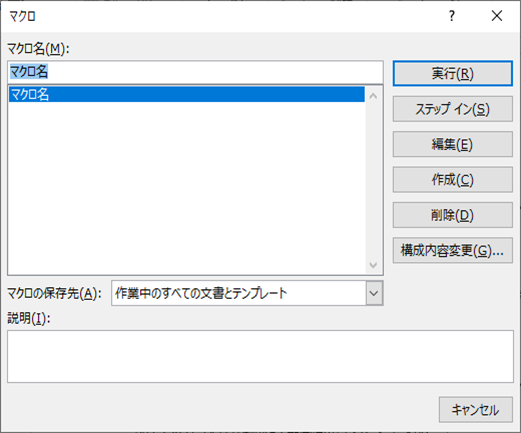
②「置換が完了しました。」が表示されたら完了です。
置換されていることを確認してみましょう。
Wordのほうは変わっていないですね…
変更前
変更後
変更前
変更後
はい!
メモ帳でみると置換されていることがわかりますね!
実はWordのほうも文字は漢字へ変換されていますが、
康煕部首の場合、自動的に「Microsoft JhengHei UI Light」という書体に変更され、
康煕部首も漢字も同じ形であるため見分けが付かないという訳だったのです。
メモ帳に貼り付けて確認した方がよいでしょう。
VBAの説明
置換リストCSVファイルを開きます。
CSV内の行数分置換処理を繰り返します。
1行分のデータを読み込みstrBufへ格納します。
文字列を”,”で分割し配列tmpへ格納します。
検索時に指定した文字列から文字列および段落の書式を削除します。
.Replacement.ClearFormatting
今回追加した箇所です。文字コードを文字へ変換し、検索ワードを代入します。
ChrW関数の式は以下の通りです。
文字コードの範囲はUnicodeの文字コード-32768から65535となります。
16進数指定なので、「&H」を頭に付けて文字コードを入力する必要があります。
置換ワードを代入します。
検索・置換の設定をおこないます。
.Forward = True
.Wrap = wdFindContinue
.Format = False
.MatchCase = True
.MatchWholeWord = False
.MatchByte = False
.MatchAllWordForms = False
.MatchWildcards = False
.MatchSoundsLike = False
.MatchFuzzy = False
Findメソッドのプロパティ設定値の詳細は以下の通りです。
| プロパティ | 説明 |
|---|---|
| Forward | (True)指定で文書に対して末尾の方向(順方向)に検索します。(False)で逆順です。 |
| Wrap | 「wdFindContinue」先頭(または末尾)に戻って検索をします。「wdFindAsk」で戻って検索をします。 |
| Format | フォーマット変更を有効する(True)、有効にしない(False)を設定します。 |
| MatchCase | 英語の大文字と小文字の区別する(True)、区別しない(False)を設定します。 |
| MatchWholeWord | 単語全体を検索対象とする(True)、しない(False)を設定します。 |
| MatchByte | 半角と全角を区別する(True)、区別しない(False)を設定します。 |
| MatchAllWordForms | 英単語の異なる活用形検索を有効する(True)、有効にしない(False)を設定します。 |
| MatchWildcards | ワイルドカード(?*など任意の文字)を使った検索を有効する(True)、有効にしない(False)を設定します。 |
| MatchSoundsLike | 英語のあいまい検索を有効する(True)、有効にしない(False)を設定します。誤った置換を防止するため、英語のあいまいな検索はOFFにします。 |
| MatchFuzzy | 日本語のあいまい検索を有効する(True)、有効にしない(False)を設定します。誤った置換を防止するため、日本語のあいまいな検索はOFFにします |
置換を全て置換で実行します。
なお、定数の種類は以下の通りです。
| 定数 | 置換の方法 |
|---|---|
| wdReplaceNone | 置換しない(既定値) |
| wdReplaceOne | 1つだけ置換 |
| wdReplaceAll | 全て置換 |
?
さいごに
いかがでしょうか。
今回は、
Word VBAを使い、康煕部首の文字を漢字など別の文字へ置換する方法
についてまとめました。
今回のVBAと置換リストをうまく活用すれば、短期間で処理ができるので、ぜひ活用いただければと思います。
この記事の関連キーワード

















コメントを残す